目前segmentfault使用的热门排序算法是根据reddit算法修改而来的,他的具体细节如下
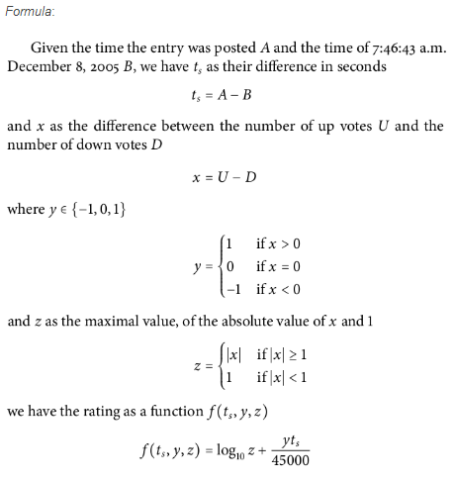
这个算法的好处在于
- 时间值被固定了,不需要像其他算法一样每次排序都要计算一次时间因子,它的分值是固定的,只需要在每次写入时计算一遍就行了
- 可以快速聚合最新最热的事件
但我们使用了一段时间后,发现它也有一个明显的缺点
这是一个新闻热点排序的算法,不适用于问答网站。它的时间影响太大,比如现在一个月内的排序,排在前面的往往是最新发布的问题,而真正评分和回答数多的问题都往后靠了,而后者才是我们希望排在前面的问题。
因此我们需要一个如下要求的算法
- 一次计算,不需要每次排序都实时计算,排序因子是一个固定值
- 时间影响在刚开始发布时影响较大,但当过了一段时间后就逐渐变小
- 主要的影响因子是问题评分和问题回答数







需求要明确,定义“刚开始发布”和“过了一段时间”的界限
1. 一次计算,不需要每次排序都实时计算,排序因子是一个固定值 这个是什么意思?你每次点up, down的时候,难道不重新计算?
图挂了。